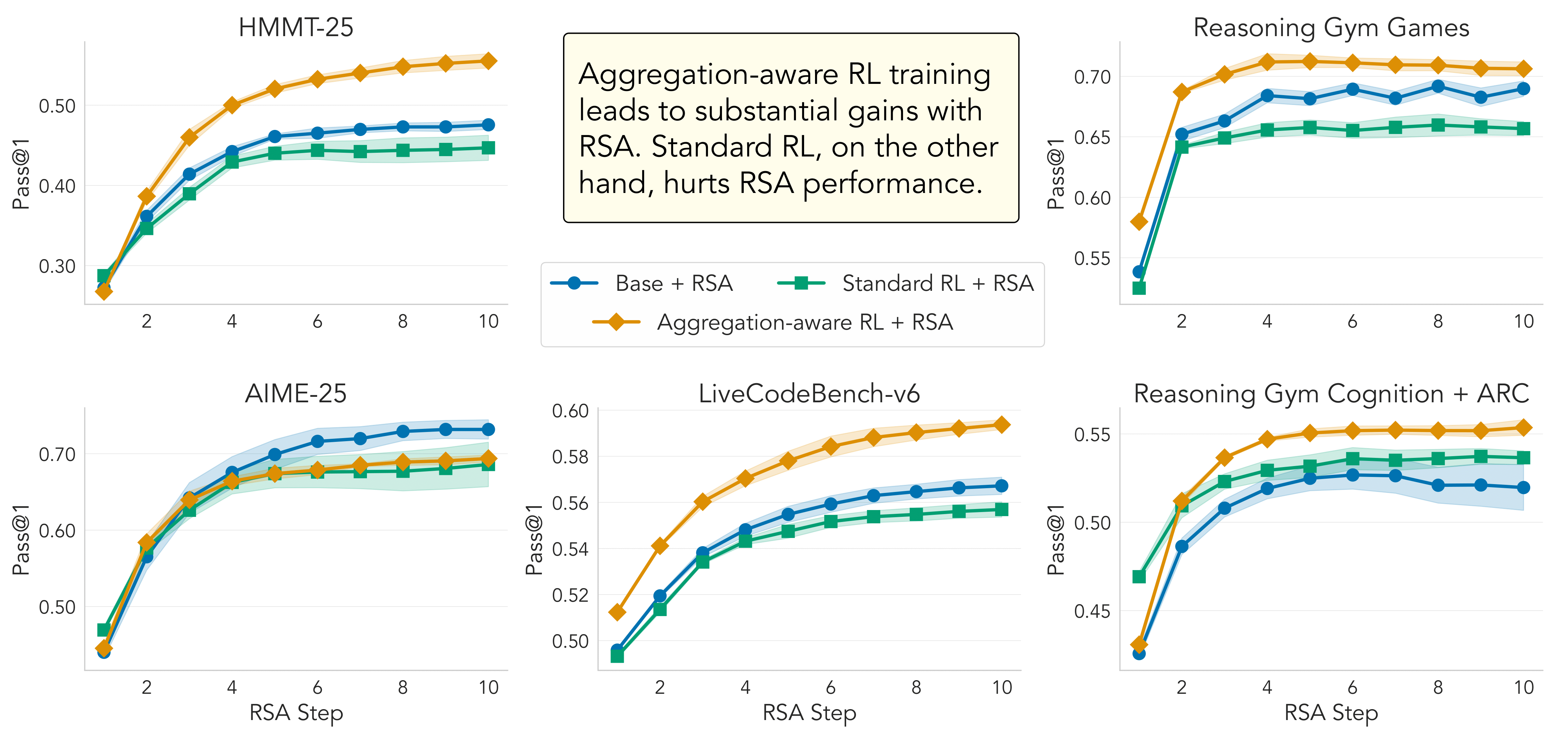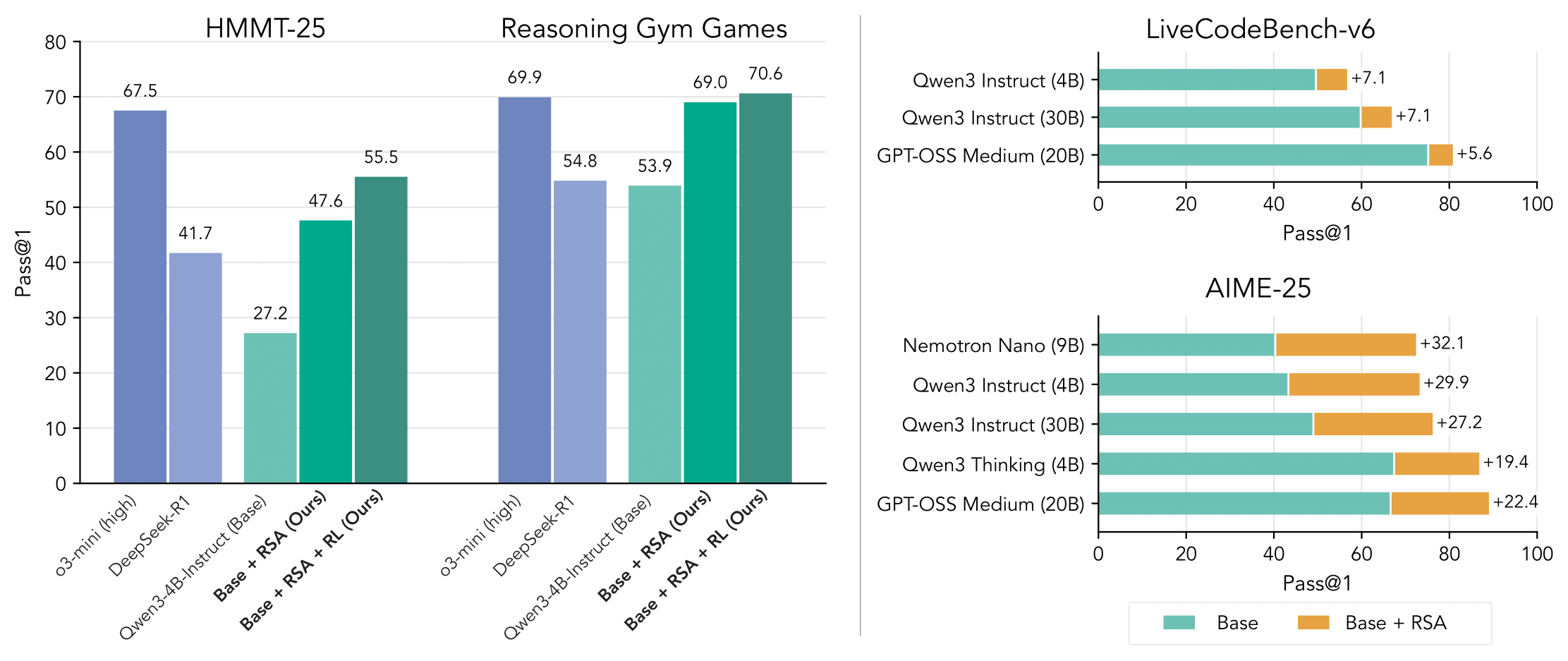
During post-training, LLMs are trained with reinforcement learning (RL) to improve their reasoning ability. RL training does not account for test-time scaling, which in this case is the task of aggregating multiple reasoning chains. In fact, we observe that standard RL fine-tuning can even degrade performance relative to the base model when combined with test-time aggregation. To address this, we propose an aggregation-aware RL approach using a simple data-augmentation strategy to train LLMs to aggregate solutions.
We present
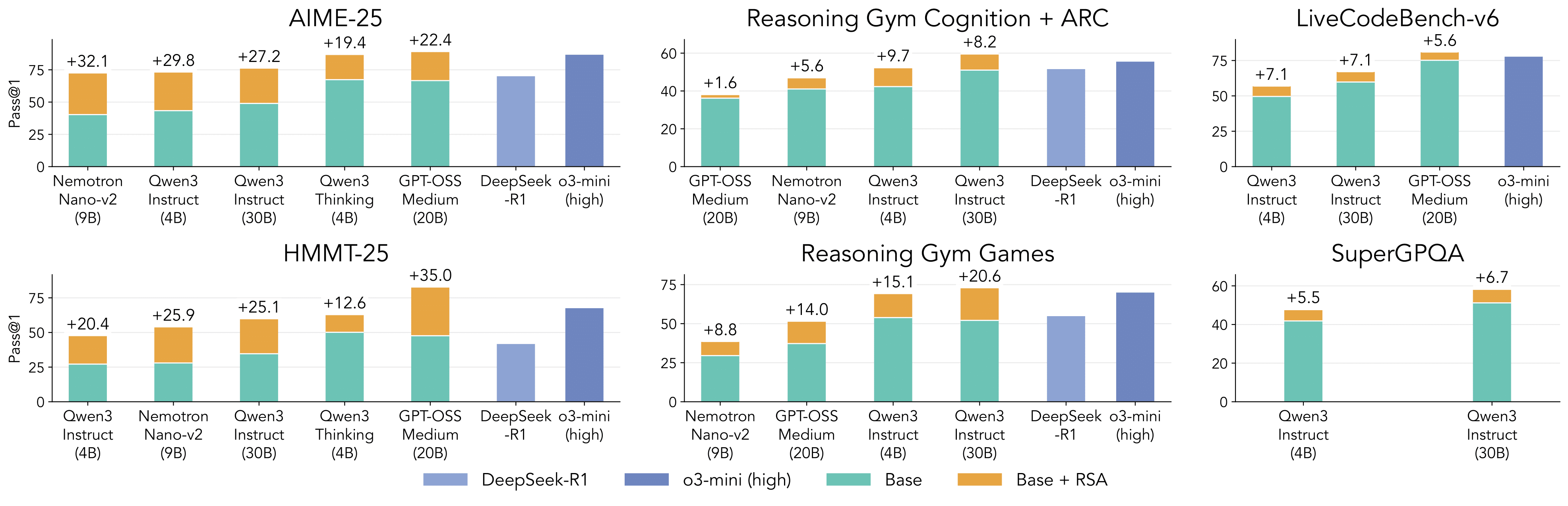
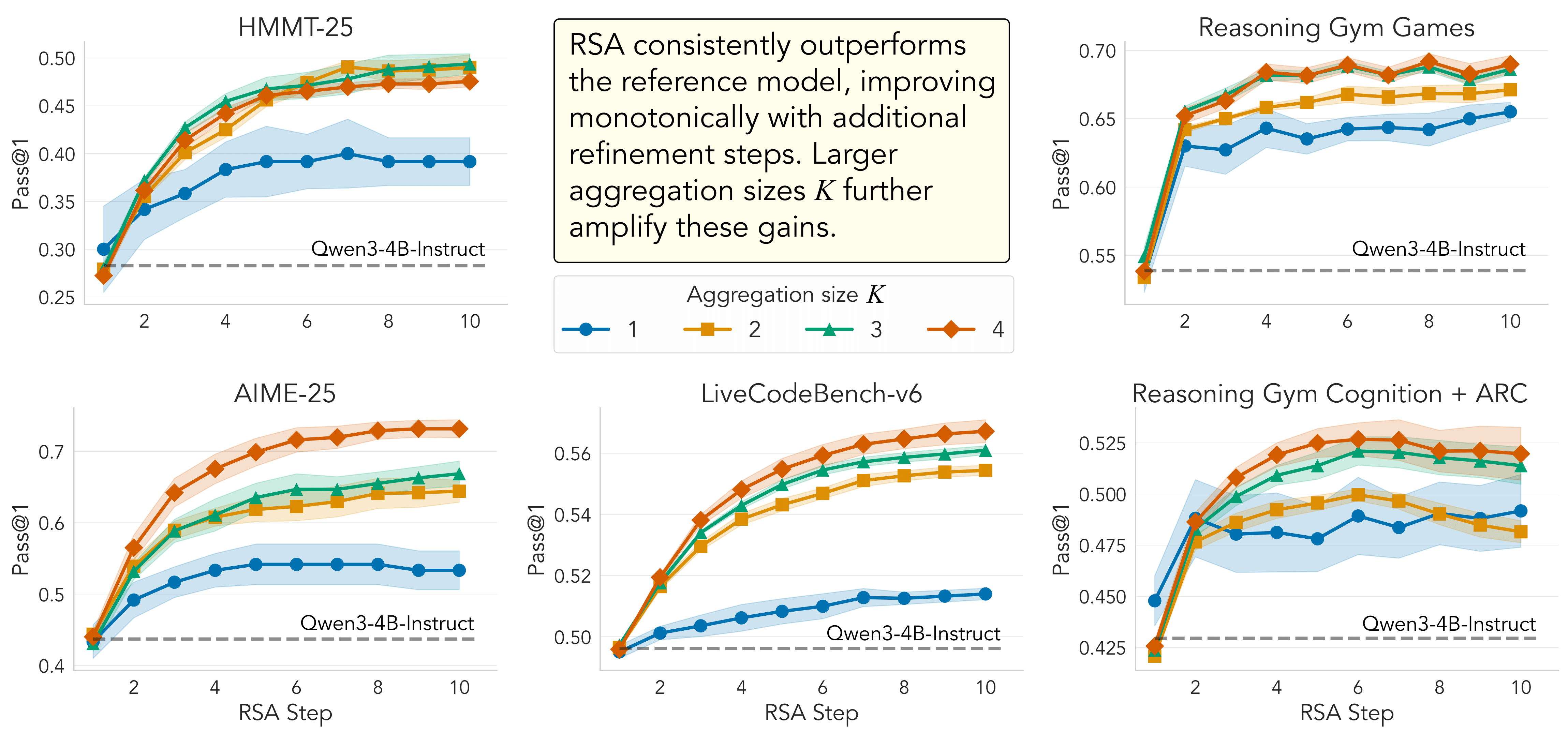
RSA is simple to implement and leads to substantial improvements in reasoning abilities across different models and tasks, when compared to pure sequential or parallel scaling.
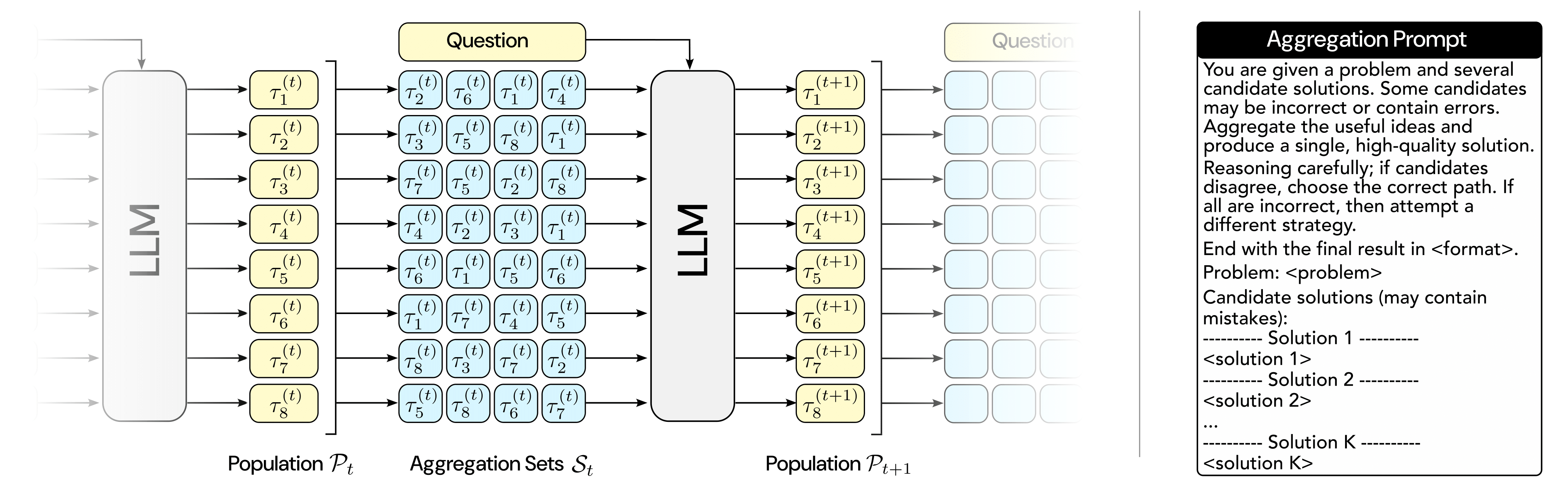
- Population of trajectories. At any given step $t$, RSA maintains a population of $N$ independent candidate solutions $\mathcal{P}_t$. The initial population $\mathcal{P}_1$ is generated by sampling $N$ responses for query $\mathbf{x}$ using the LLM $p_{\theta}$.
- Subsampling. We form $N$ aggregation sets of $K$ candidates, where each set is sampled uniformly without replacement from the population.
- Aggregation. Each set of candidates and the query $\mathbf{x}$ is formatted using an aggregation prompt directing the LLM $p_{\theta}$ to generate a refined response $\tau_{i}^{(t+1)}$, forming a new population of candidates $\mathcal{P}_{t+1}$. RSA recursively updates the population $\mathcal{P}_t$ using subsampling and aggregation for $t=1,\dots,T-1$. This sequential loop is expected to allow errors and inconsistencies to be gradually pruned away during aggregation, while preserving favorable reasoning patterns. Consequently, we expect overall diversity within the population to generally decrease as $t$ increases, accompanied by a monotonic improvement in success rate.
- Termination. Given the final population of candidate solutions $\mathcal{P}_T$, the solution is obtained either by randomly sampling from this population or by majority voting. We use uniform random sampling in all our experiments, to evaluate our method without any special selection mechanism.